豆瓣热门电影评论爬虫
环境
- Python36
- Chrome
- 分词库:jieba 词云:wordcloud 解析DOM:beautifulsoup4 绘图:matplotlib 数据处理:pandas, numpy
- 以上模块均可通过
pip install **安装 - 学会Google, Baidu, 看博客
开始吧^_^
网页分析
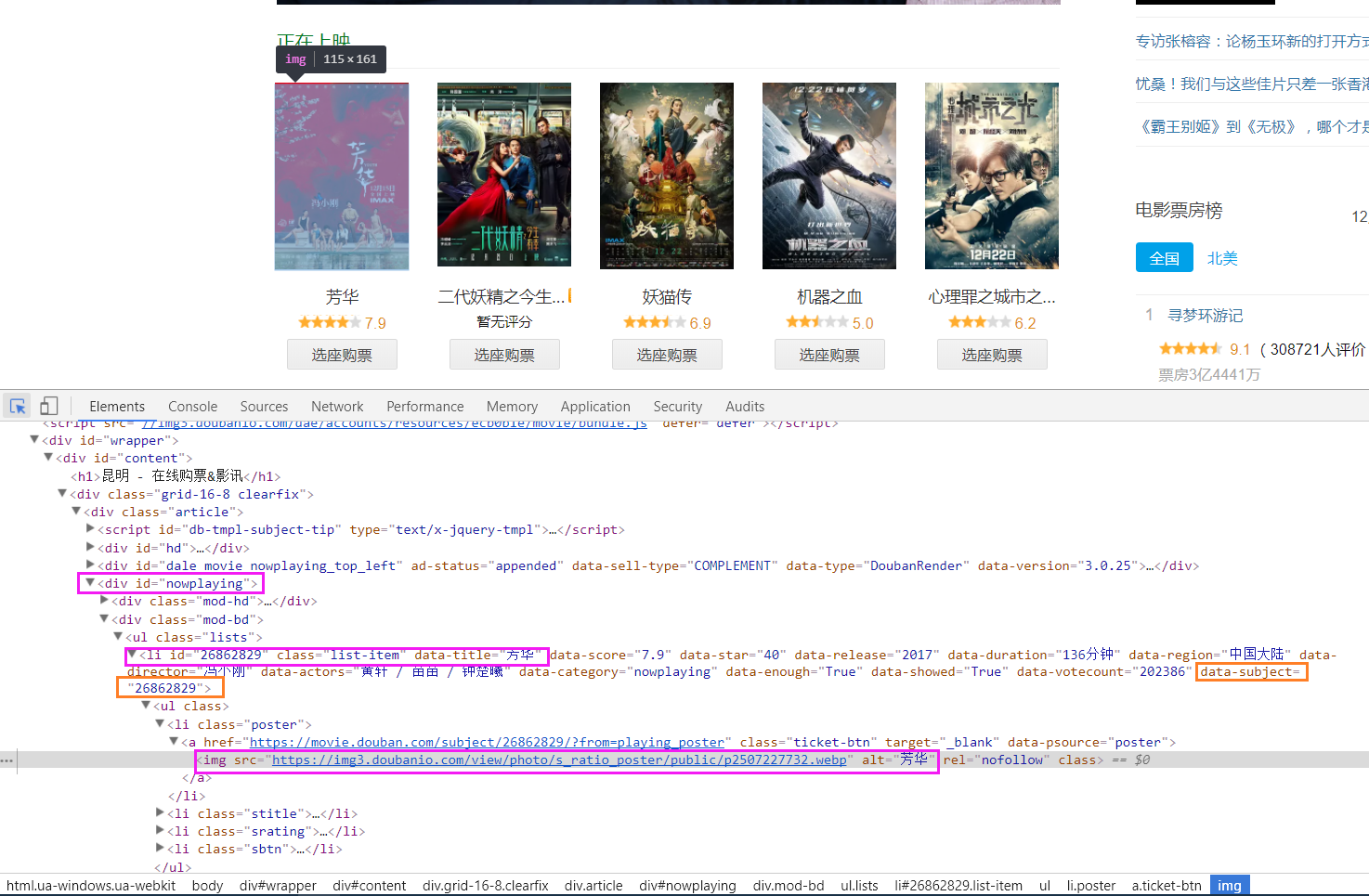
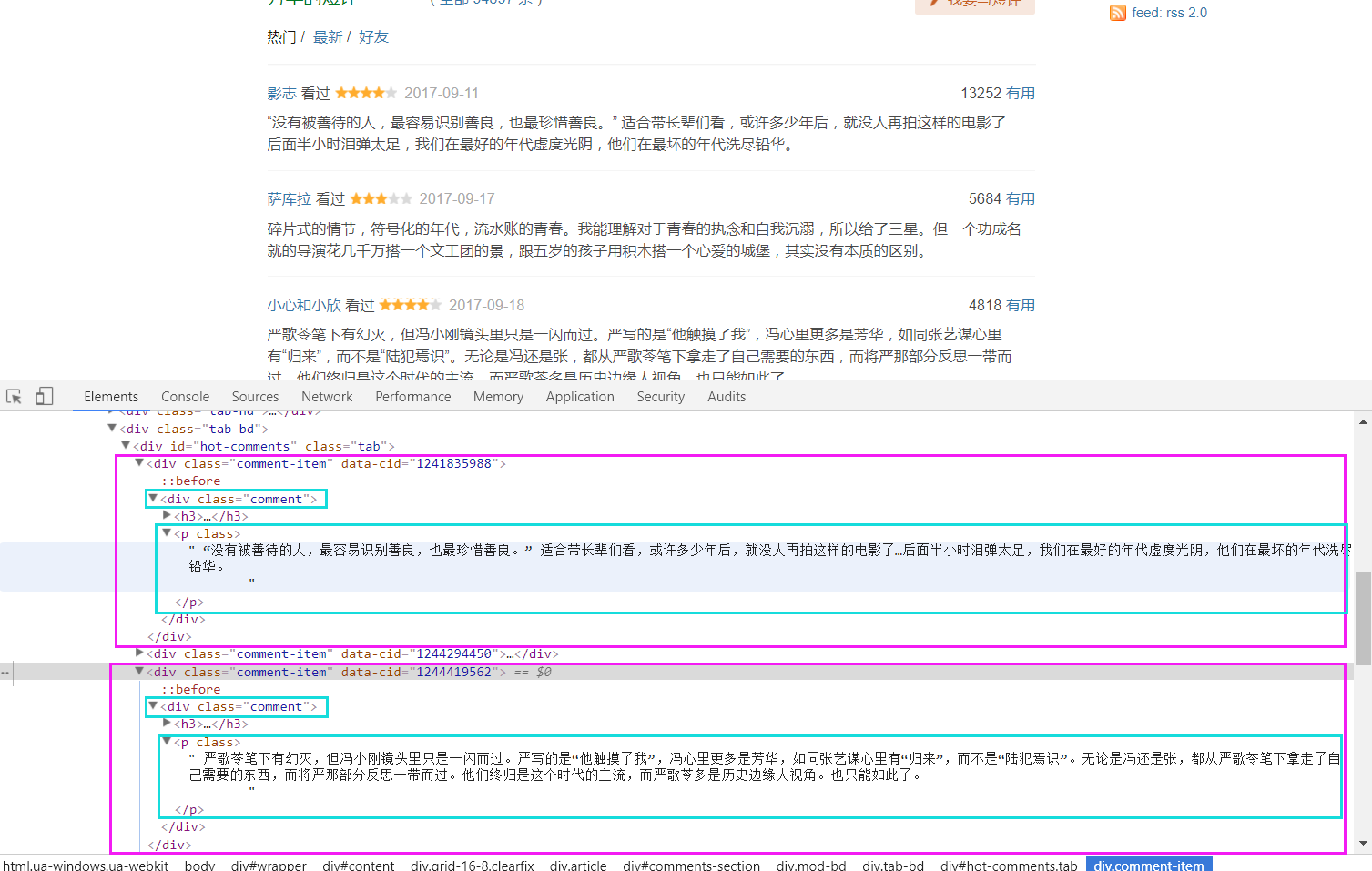
直接上代码,注释很详细
|
|
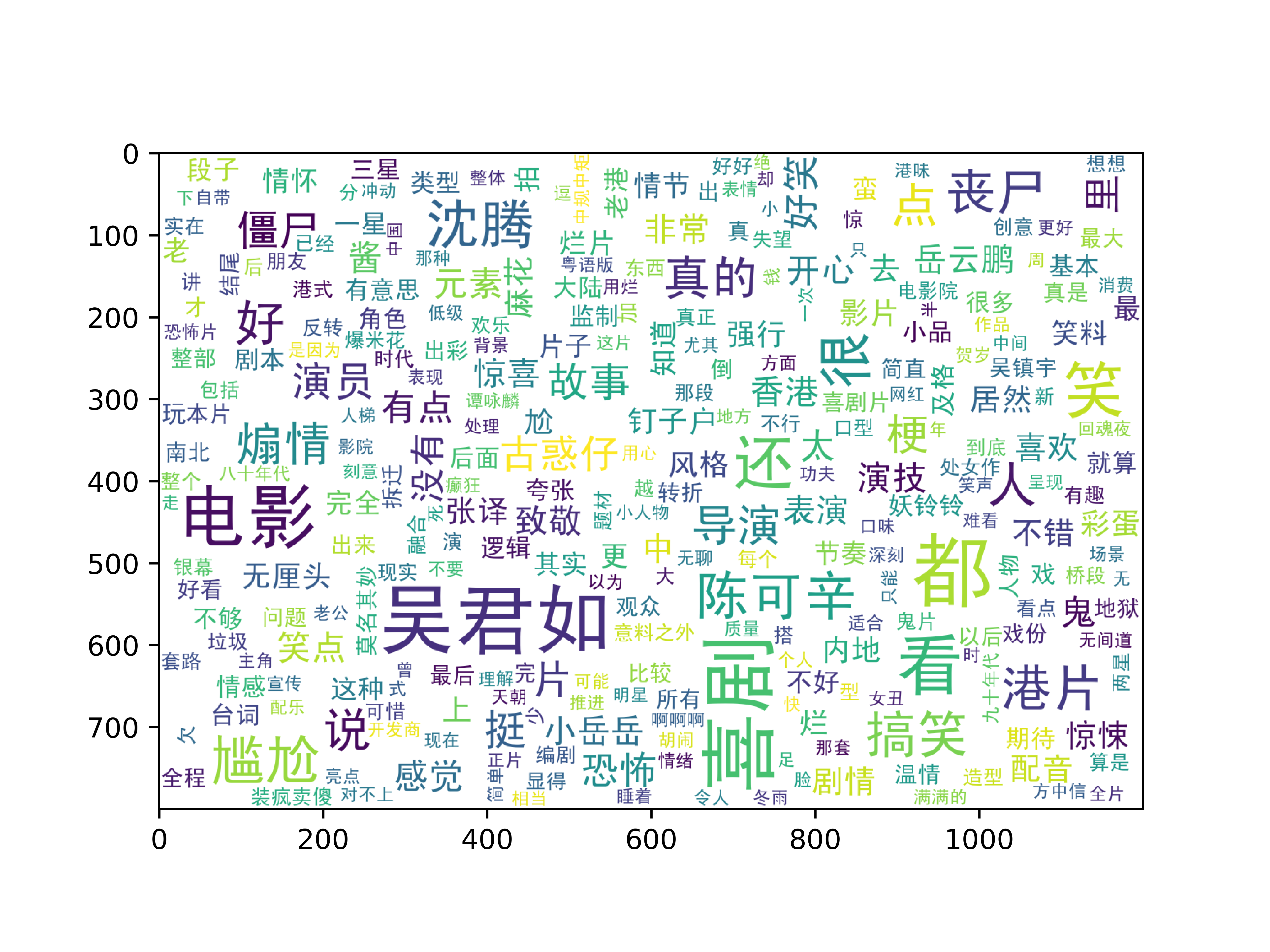
结果展示
时光不停 TeslaChan @buting
转载请注明出处!
转载请注明出处!